We recently added support for writing complex expressions directly inside node inputs in Midio. This makes it easier to work with data and perform calculations without needing extra nodes.
In this article, I’ll walk through some of the challenges we faced while implementing this feature, including handling invalid expressions, keeping connections intact during edits, and designing an intuitive syntax. I’ll also share some key design decisions and the reasoning behind them.
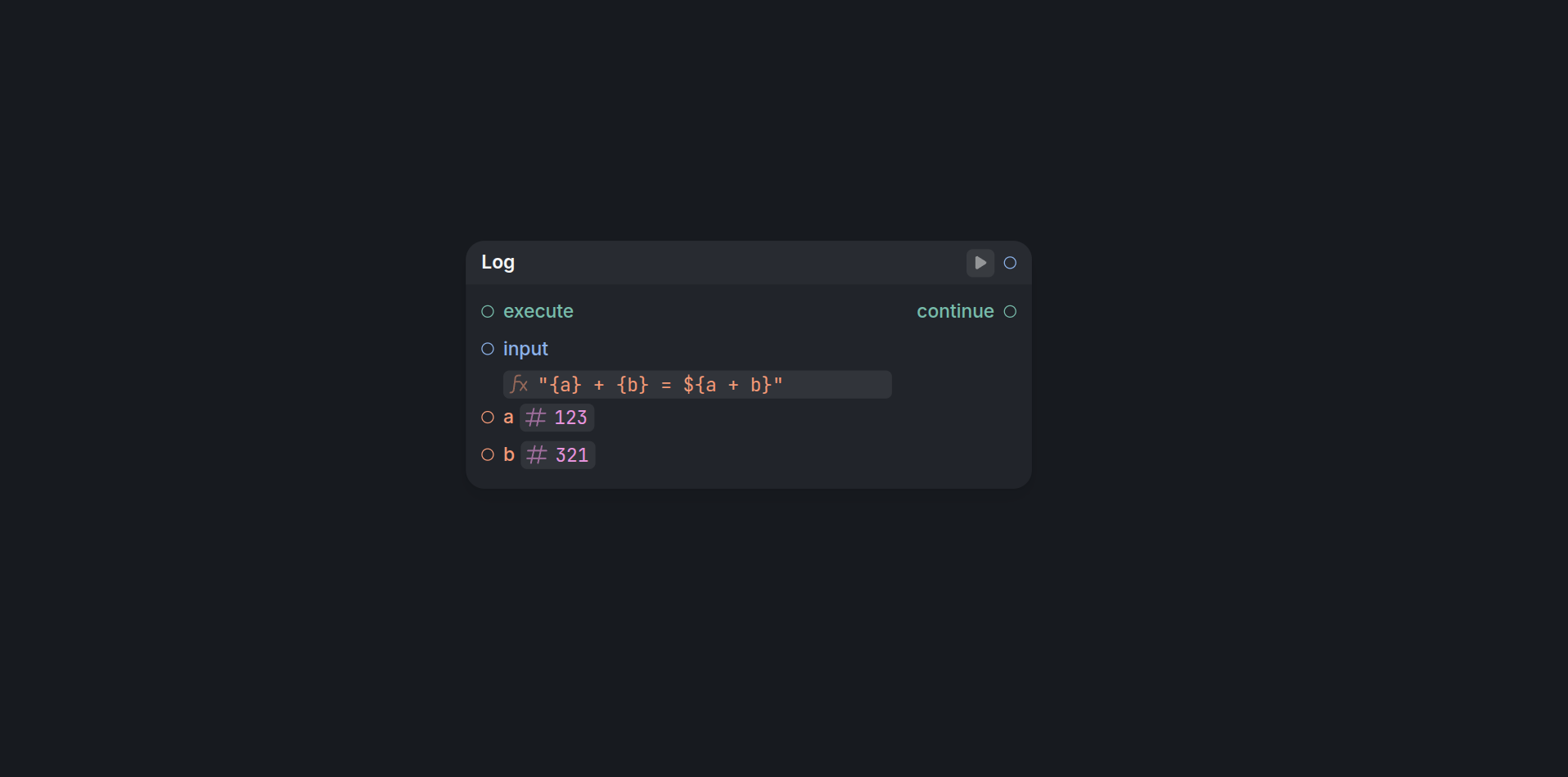
The expression syntax resembles any JavaScript-like language, and supports literals (strings, numbers, bools, objects and lists), unary and binary operators like +, -, * and /, the dot (foo.bar) and index (foo[1]) operator, and the ternary operator (x ? y : z). We also support the null-coalescing operator (foo ?? bar). We also added support for string interpolation: «Hello ${1 + 2}».
In order for an expression to get inputs from other nodes, any identifier in the expression will add a special expression-input on the node which allows you to connect values like you would any other input to that expression.
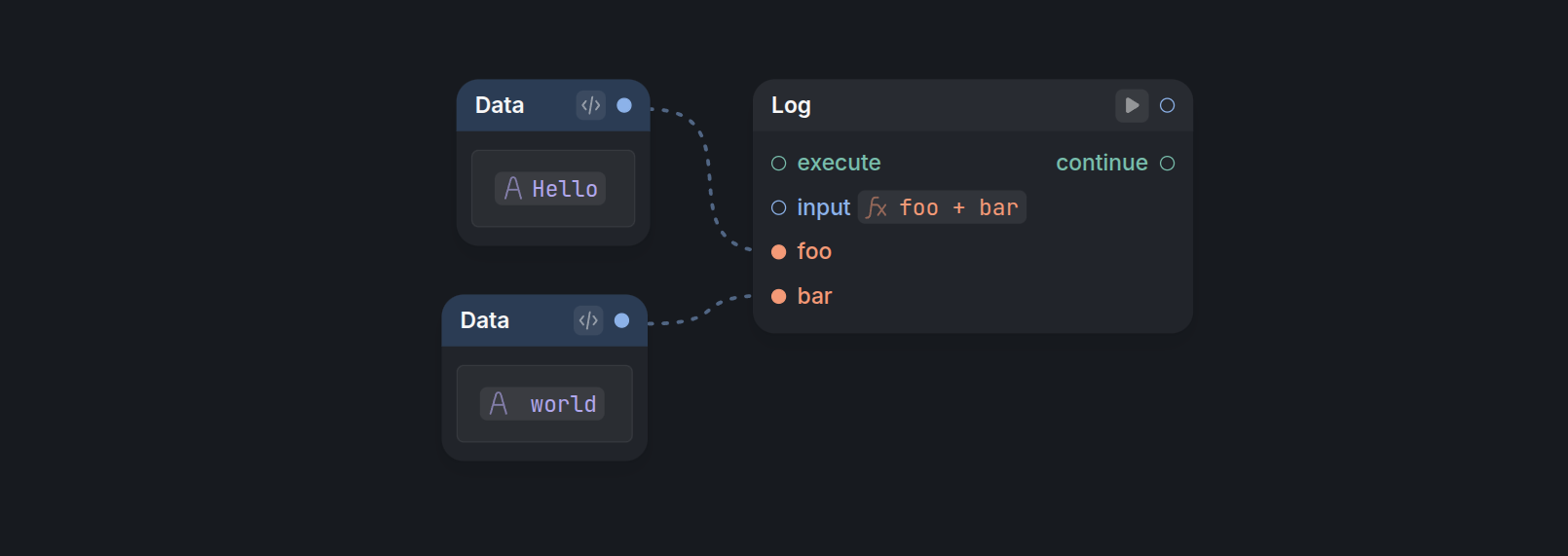
The expression feature has proven especially valuable for cases that are less suited to node-based programming, such as complex mathematical expressions.
Challenges implementing it
Making the Compiler More Forgiving: Handling Unparsable Expressions
Up until now, every user edit in Midio would take the code from one valid state into a new one. This meant that there would be no way for the user to put the code into an unparsable state.
This is no longer the case, as users can write invalid expressions, which we need to handle gracefully.
We solved this by surrounding each expression in a set of delimiters, and by always escaping these delimiters when receiving an expression from the user. This way, if the expression didn’t parse, we can just keep consuming tokens until we find a 'right' closing delimiter, store the expression as a special UnparsedExpression type, and keep going.
We represent expressions as follows:
let repr_identifier_1 = #{ a + b #}
The identifier is used when connecting arrows to inputs on the expression, which looks like this in code:
123 -> repr_identifier_1.a
321 -> repr_identifier_1.b
We chose #{ and #} as expression delimiters because they provide a clear distinction between opening and closing markers while remaining easy to identify in the code. Since both start with #, they are visually linked, but their differing second characters ensure there’s never ambiguity about whether we're looking at the start or end of an expression. Using a multi-character delimiter also reduces the likelihood of accidental conflicts with user-written code, making it a safer choice in a system where expressions are embedded in a larger syntax. For example, if we used { and }, we'd have no reliable way to distinguish between an expression block and an object literal.
The expression parser
The expressions are parsed using a standard pratt parsing/precedence climbing technique, to handle operator precedence properly. Not much interesting here.
Interpolated strings
Getting string interpolation to work turned out to be slightly involved. Our tokenizer always handled string literals by assuming they would be a single run of characters from one opening “ to closing one. This is no longer the case, as a string literal might have to be split up into multiple parts to handle internal expressions.
"Hello ${a + b} world"
is now tokenized as:
- `StringLiteralOpenDelimiter(<">)`
- `StringLiteralSegment(<Hello >)`
- `StringLiteralSubExprOpenDelimiter(<${>)`
- `Identifier(<a>)`
- `Operator(<+>)`
- `Identifier(<b>)`
- `StringSubExprCloseDelimiter(<}>)`
- `StringLiteralSegment(< world>)`
- `StringLiteralCloseDelimiter(<">)`
Our tokenizer used to be almost stateless in terms of what token it would recognise next, but it now needs to maintain keep track of whether we are in the middle of a string or not in order to produce the correct tokens.
The tokenizer looks for a « character, and starts an interpolated string segment, noting this in the context. While in this context, each character is consumed as part of the literal segment. If it finds a ${ token, it closes the string segment, and emits it as a token. It then changes to context so we no longer tokenize as if we are in a string literal. When we find a matching }, we reenter the string literal context. Since we can nest literals and sub expressions, we need to maintain a 'context stack'.
Nested literals:
#{ "Hello ${ "world ${a}" }" }
Design choice - String literal syntax
When it comes to string literal syntax design, we had to make two major decisions:
- Do we use different string delimiters for interpolated strings, or do we make all string potentially interpolated (for example, javascript uses back ticks (`) to delimit interpolated strings.
- What delimiter to use for inner expressions
For the first question, we decided to go with a single set of delimiters, meaning all strings can have inner expressions. This is the less common option for programming languages, but we felt it matched well with our target audience, and means there's less syntax to learn.
We went with ${ and } as delimiters for inner expressions. This is mainly because it matches JavaScript/TypeScript, and should be familiar to the most number of people. The other option we considered was only { and }. The main downside with that option is that the user would have to escape all uses of those characters in their strings, which we decided was not worth it.
Rust does strings this way, and lets you escape the delimiters with double curlies, e.g. {{ and }}. But since we expect a common use-case for strings in Midio is inline code examples for an LLM to consume, we decided this was not a good solution for us.
Editing challenges
Nested expressions
It is possible for the user to write expressions in the input to an expression.
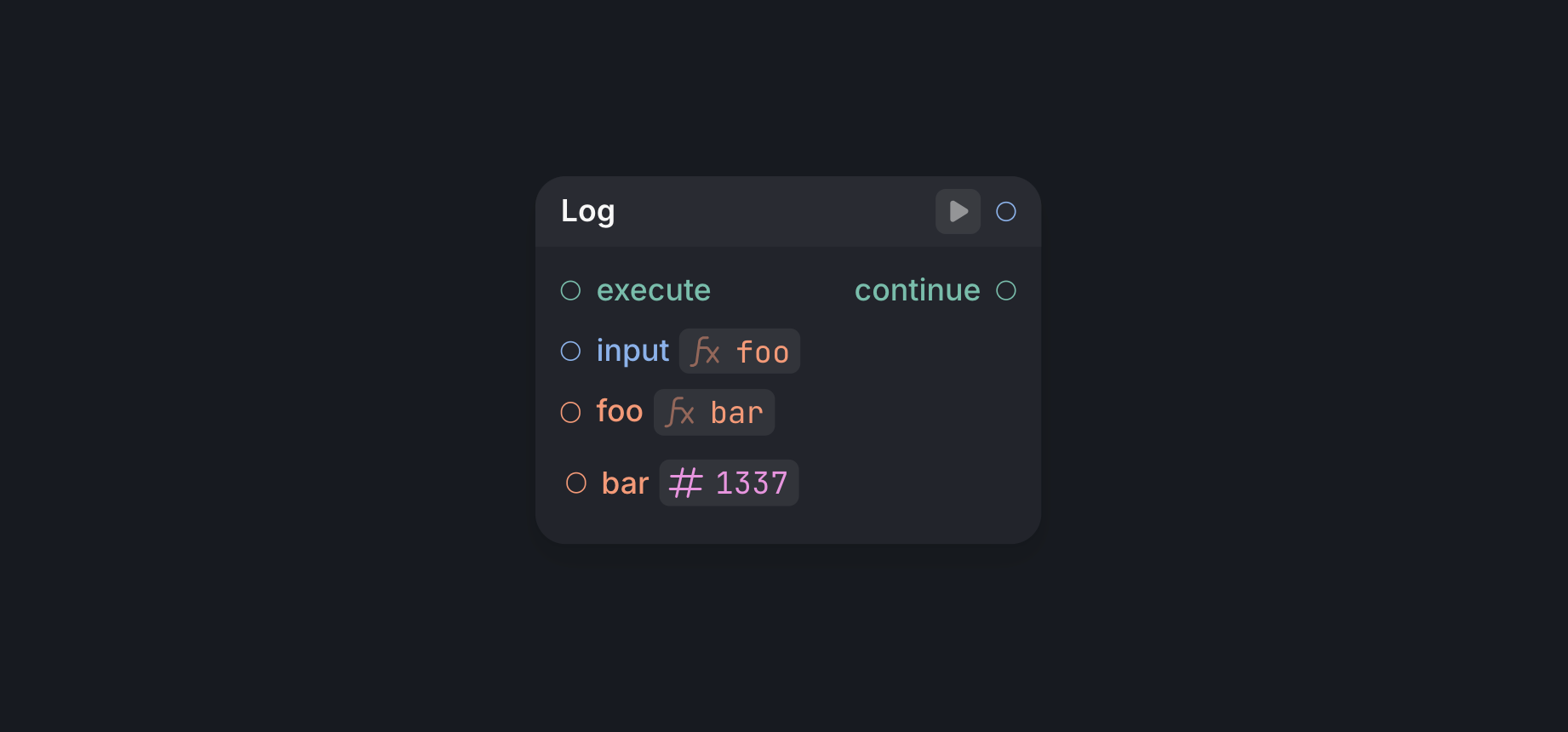
The node above is represented in code as two let declarations.
instance log_1 Std.Log {} // The Log node itself
let expr_1 = #{ foo }
let expr_2 = #{ bar }
1337 -> expr_2.bar
expr_2 -> foo.bar
expr_1 -> log_1.input
When we delete a node, we also delete any arrow pointing to it. Before expressions, we could do this easily by finding all arrows pointing to an input or from an output of that node, and delete them.
This is no longer sufficient, as stopping there would lead to the let declarations sticking around, and we would end up with:
let expr_1 = #{ foo }
let expr_2 = #{ bar }
1337 -> expr_2.bar
expr_2 -> foo.bar
To fix this, we now follow arrows going from let declarations, which we then delete. Since let declarations also can have arrows pointing to them, we need to do this operation recursively, effectively performing a depth first search.
Stable arrows
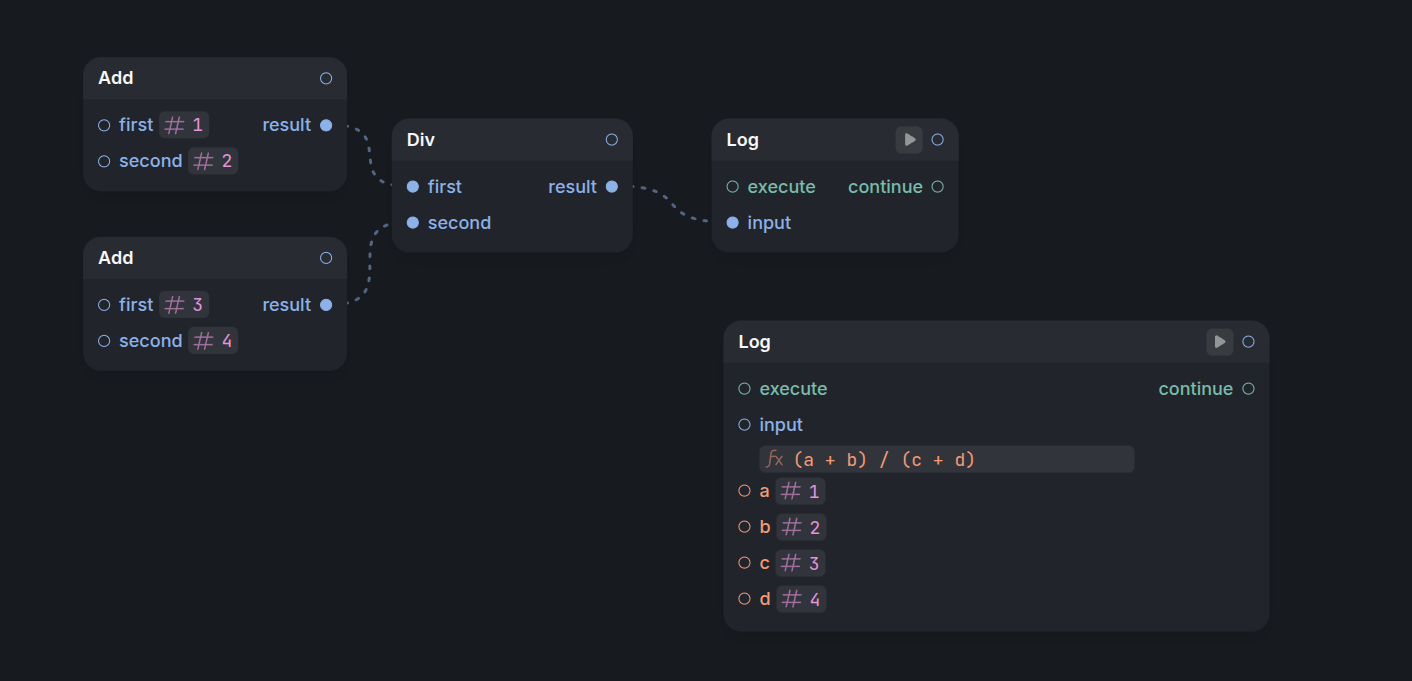
The biggest challenge with editing expressions is keeping arrows correctly connected to inputs as the expression changes. If a user renames an input, adds a new one, or removes an existing one, we need to ensure that arrows pointing to invalid inputs are removed to prevent broken connections.
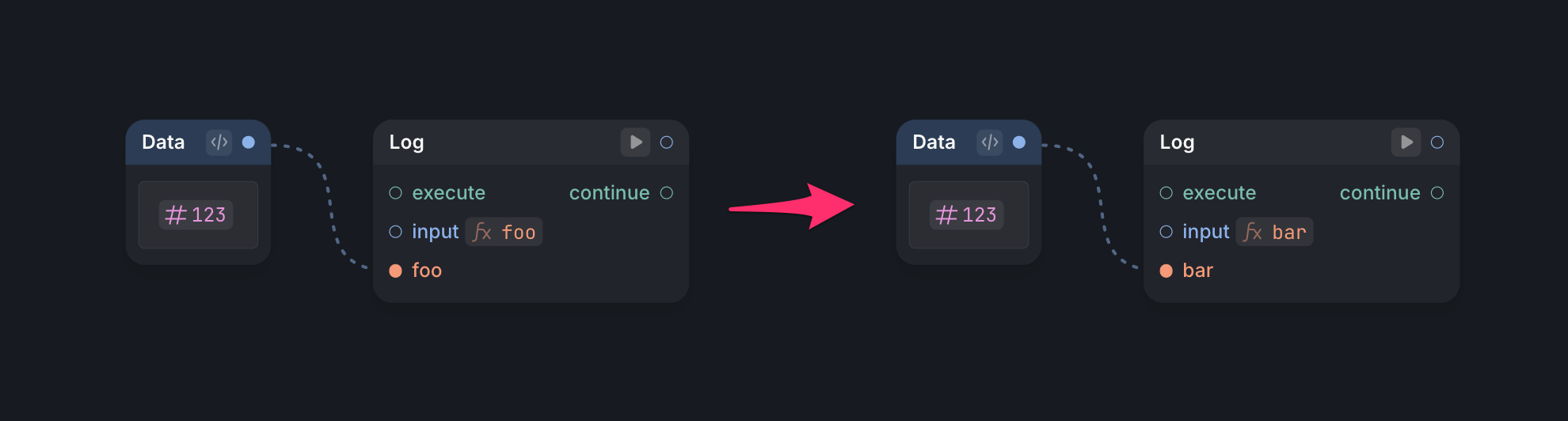
In this example, we renamed foo to bar, and we expect the arrow from 123 to remain there.
I'm sure we can improve our currently solution significantly, but as an MVP, we've gone with the following heuristic:
- First, remove all incoming arrows to avoid invalid connections.
- Update the expression
- Try to reapply the arrows with the following strategy
- For each remaining disconnected arrow: If an input with the same name still exist, connect to it
- For each arrow still disconnected: if there is an input with no arrow to it, we connect to that.
This heuristic is designed to handle the three most common user actions:
- renaming:
a + b->c + dis treated as renamingatocandbtod - moving:
a + b->b + ais treated asaandbswitching place - deletion:
a + b->bis treated asabeing removed as the arrow is just not reconnected
To the editor, an expression is just text, so we have no structural way of understanding what kind of operation the user was trying to perform with respect to inputs; whether they intended to add, remove, rename or move. We do our best to figure this out by correlating the new expression with the previous one.
There is one major flaw to this solution. If the new expression doesn't parse, we can't re-add any arrows because we have no way to analyse its structure.
One possible improvement is temporarily storing the previous arrows and attempting to reapply them once the expression becomes valid again.
Reflections
Working on a visual language brings a unique set of problems—some familiar from traditional languages, but often requiring different solutions. Lenient parsing, for example, is important in any language, but in a visual system like Midio, handling syntactic errors gracefully becomes even more critical.
We have plenty of ideas for expanding the expression system in the future, including direct function calls, anonymous functions, and closures. I’m looking forward to exploring those, but for now, I’m quite happy with the set of features we landed on.